How to Submit Raw Reads
Introduction
To submit raw read sequencing data to ENA you must also provide some metadata to describe your sequencing project. This helps make your data re-useable and searchable.
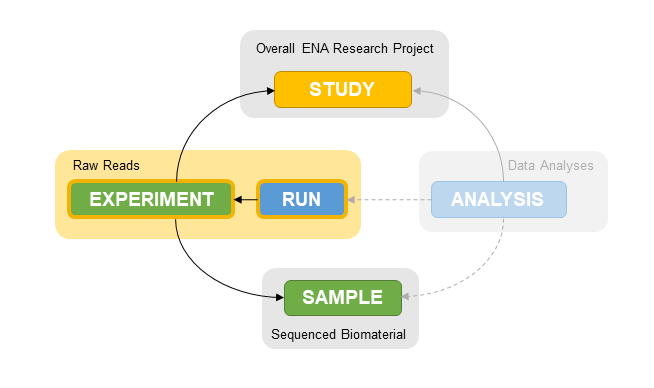
Within ENA, raw reads are represented as ‘run’ and ‘experiment’ submission objects.
The run submission holds information about the raw read files generated in a run of sequencing as well as their location on an FTP server.
The experiment submission holds metadata that describe the methods used to sequence the sample.
If you are not yet familiar with the metadata model, please see here for some more information.
As a raw read submission references ENA sample and study objects, you must submit these before you can submit your read data. See below for information on how to register a study within ENA to describe your project and samples with information on the biological material which was sequenced:
Accessions
Once the raw reads are registered, Webin will report two unique accession numbers for each read submission. The first starts with ERR and is called the Run accession. The other starts with ERX and is called the Experiment accession.
Always make a note of any accessions you receive as these are the unique identifiers for each of your submissions to ENA. You can always review your read submissions within the interactive submission interface.
Submission Options
Reads can be submitted in any of three ways.
For an overview of these, please see the General Guide on Submitting to ENA.
Note
Webin-CLI is recommended for read submissions because it provides the best pre-submission validation, however note that in the read context it is only usable for data in FASTQ, BAM, or CRAM formats